Tolkingen av skogvariabler (volum, treslag, alder) blir gjort automatisk av et program som sammenstiller feltdata fra Landsskogtakseringen med kart og satellittbilder. En skogmaske brukes for å skille skog fra andre arealtyper, og kun arealet innfor skogmaska blir tolket.
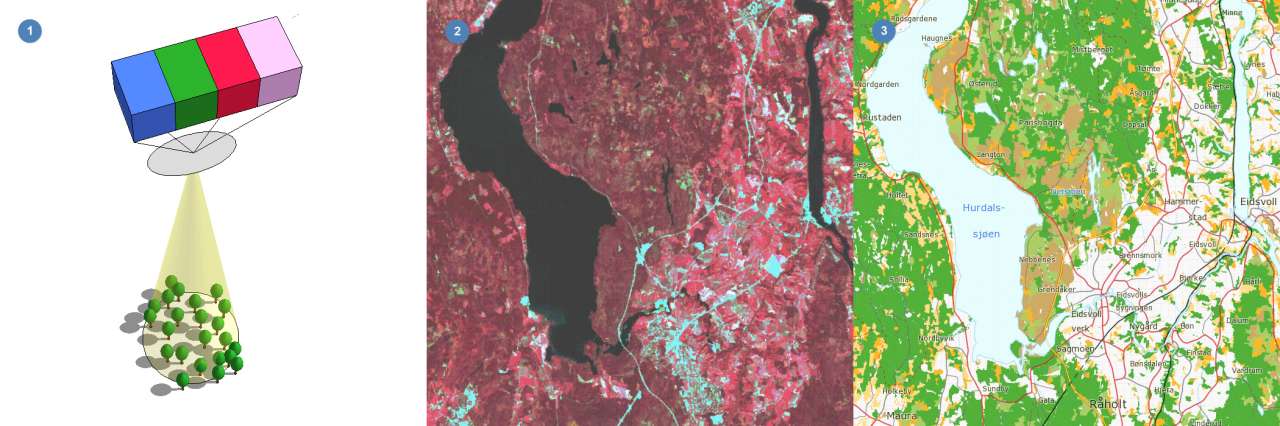
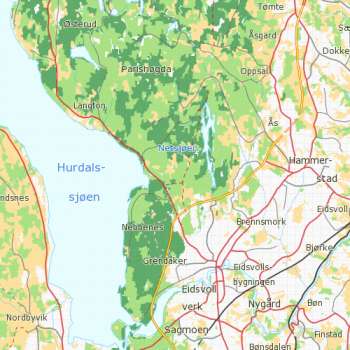
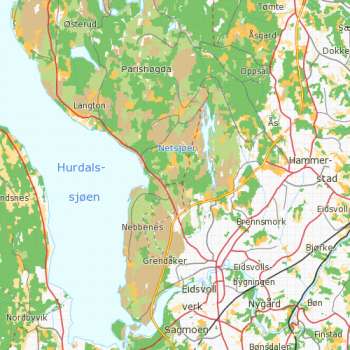
Kart over treslagsfordeling med satellittbilde som bakgrunn. Grønt er granskog, lysebrunt er furuskog og rødt er lauvskog. Satellittbildet består av mange punkter eller piksler med verdier fra flere spektrale bånd som satellittens sensor måler i. Eksempler på spektrale bånd er blått, grønt, rødt og nærinfrarødt lys.
Piksler som dekker en Landsskogflate blir brukt som referansepiksler og har en kjent skogsituasjon. For alle andre piksler i skogmaska er skogsituasjonen ukjent og må tolkes.
Programmet tolker (estimerer) en ukjent piksel, P, ved å sammenligne med referansepikslene og plukke ut de referansepikslene som er mest lik P. Typisk vil fra 1 til 12 referansepiksler plukkes ut og disse utgjør nabopikslene til P. Nabopikslene brukes så for å estimere skogvariabler for P. For å lage lesbare kart blir like piksler gruppert i sammenhengende arealfigurer hvor skogsituasjonen er relativt ensartet. Resultatet av denne automatiske prosessen er et vektorkart.
Skogtype og skogtilstand gir ulik refleksjon av sollyset i de spektrale båndene og dette gir grunnlag for å skille mellom treslag, alder- og volumklasser. Sammenhengen mellom variablene og refleksjon av sollyset er imidlertid ikke perfekt, og nøyaktigheten på estimatene for enkeltpiksler vil derfor være relativt lav. Men siden feilen i estimatene for enkeltpiksler er tilfeldig, vil summering av estimatene over arealer med mange piksler føre til større nøyaktighet enn for enkeltpiksler.

-%20foto%20esa_cropped.jpg?quality=60)